
1. Overview
AI-powered applications are our new reality. We’re widely implementing various RAG applications, and prompt APIs, and creating impressive projects using LLMs. With Spring AI, we can accomplish these tasks faster and more consistently.
In this article, we’ll review a valuable feature called Spring AI Advisors, which can handle various routine tasks for us.
2. What Is Spring AI Advisor?
Advisors are interceptors that handle requests and responses in our AI applications. We can use them to set up additional functionality for our prompting processes. For example, we might establish a chat history, exclude sensitive words, or add extra context to each request.
The core component of this feature is the CallAroundAdvisor interface. We implement this interface to create a chain of Advisors that’ll affect our requests or responses. The advisors’ flow is described in this diagram:
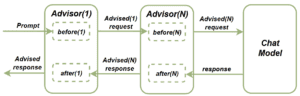
We send the prompt to a chat model attached to a chain of advisors. Before the prompt is delivered, each advisor from the chain performs its before action. Similarly, before we get the response from the chat model, each advisor calls its own after action.
3. Chat Memory Advisors
Chat Memory Advisors is a pretty useful set of Advisor implementations. We can use these Advisors to provide a communication history with our chat prompt, improving chat response accuracy.
3.1. MessageChatMemoryAdvisor
Using MessageChatMemoryAdvisor we can provide a chat history with chat client calls using the messages property. We save all the messages in a ChatMemory implementation and can control the history size.
Let’s implement a simple showcase for this advisor:
@SpringBootTest(classes = ChatModel.class)
@EnableAutoConfiguration
@ExtendWith(SpringExtension.class)
public class SpringAILiveTest {
@Autowired
@Qualifier("openAiChatModel")
ChatModel chatModel;
ChatClient chatClient;
@BeforeEach
void setup() {
chatClient = ChatClient.builder(chatModel).build();
}
@Test
void givenMessageChatMemoryAdvisor_whenAskingChatToIncrementTheResponseWithNewName_thenNamesFromTheChatHistoryExistInResponse() {
ChatMemory chatMemory = new InMemoryChatMemory();
MessageChatMemoryAdvisor chatMemoryAdvisor = new MessageChatMemoryAdvisor(chatMemory);
String responseContent = chatClient.prompt()
.user("Add this name to a list and return all the values: Bob")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Bob");
responseContent = chatClient.prompt()
.user("Add this name to a list and return all the values: John")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Bob")
.contains("John");
responseContent = chatClient.prompt()
.user("Add this name to a list and return all the values: Anna")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Bob")
.contains("John")
.contains("Anna");
}
}3.2. PromptChatMemoryAdvisor
Use the conversation memory from the MEMORY section to provide accurate answers.
---------------------
MEMORY:
{memory}
---------------------Let’s verify how it works:
@Test
void givenPromptChatMemoryAdvisor_whenAskingChatToIncrementTheResponseWithNewName_thenNamesFromTheChatHistoryExistInResponse() {
ChatMemory chatMemory = new InMemoryChatMemory();
PromptChatMemoryAdvisor chatMemoryAdvisor = new PromptChatMemoryAdvisor(chatMemory);
String responseContent = chatClient.prompt()
.user("Add this name to a list and return all the values: Bob")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Bob");
responseContent = chatClient.prompt()
.user("Add this name to a list and return all the values: John")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Bob")
.contains("John");
responseContent = chatClient.prompt()
.user("Add this name to a list and return all the values: Anna")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Bob")
.contains("John")
.contains("Anna");
}Again, we’ve tried to create a few prompts asking a chat model to consider the conversation memory using the PromptChatMemoryAdvisor this time. And as expected, all the data was returned to us correctly.
3.3. VectorStoreChatMemoryAdvisor
Using VectorStoreChatMemoryAdvisor, we obtain more powerful functionality. We search the context of messages via similarity matching in the vector store. We take the conversation ID into account searching the related documents. For our example, we’ll take a slightly overridden SimpleVectorStore but we also can replace it with any Vector database.
First of all, let’s create a bean of our vector store:
@Configuration
public class SimpleVectorStoreConfiguration {
@Bean
public VectorStore vectorStore(@Qualifier("openAiEmbeddingModel")EmbeddingModel embeddingModel) {
return new SimpleVectorStore(embeddingModel) {
@Override
public List<Document> doSimilaritySearch(SearchRequest request) {
float[] userQueryEmbedding = embeddingModel.embed(request.query);
return this.store.values()
.stream()
.map(entry -> Pair.of(entry.getId(),
EmbeddingMath.cosineSimilarity(userQueryEmbedding, entry.getEmbedding())))
.filter(s -> s.getSecond() >= request.getSimilarityThreshold())
.sorted(Comparator.comparing(Pair::getSecond))
.limit(request.getTopK())
.map(s -> this.store.get(s.getFirst()))
.toList();
}
};
}
}Here we’ve created a bean of SimpleVectorStore class and overrided its doSimilaritySearch() method. The default SimpleVectorStore doesn’t support metadata filtering and here we’ll ignore this fact. Since we’ll have only one conversation during the test, this approach perfectly suits us.
Now, let’s test the history context behavior:
@Test
void givenVectorStoreChatMemoryAdvisor_whenAskingChatToIncrementTheResponseWithNewName_thenNamesFromTheChatHistoryExistInResponse() {
VectorStoreChatMemoryAdvisor chatMemoryAdvisor = new VectorStoreChatMemoryAdvisor(vectorStore);
String responseContent = chatClient.prompt()
.user("Find cats from our chat history, add Lion there and return a list")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Lion");
responseContent = chatClient.prompt()
.user("Find cats from our chat history, add Puma there and return a list")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Lion")
.contains("Puma");
responseContent = chatClient.prompt()
.user("Find cats from our chat history, add Leopard there and return a list")
.advisors(chatMemoryAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("Lion")
.contains("Puma")
.contains("Leopard");
}4. QuestionAnswerAdvisor
@Test
void givenQuestionAnswerAdvisor_whenAskingQuestion_thenAnswerShouldBeProvidedBasedOnVectorStoreInformation() {
Document document = new Document("The sky is green");
List<Document> documents = new TokenTextSplitter().apply(List.of(document));
vectorStore.add(documents);
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(vectorStore);
String responseContent = chatClient.prompt()
.user("What is the sky color?")
.advisors(questionAnswerAdvisor)
.call()
.content();
assertThat(responseContent)
.containsIgnoringCase("green");
}5. SafeGuardAdvisor
Sometimes we must prevent certain sensitive words from being used in client prompts. Undeniably, we can use SafeGuardAdvisor to achieve this by specifying a list of forbidden words and including them in the prompt’s advisor instance. If any of these words are used in a search request, it’ll be rejected, and the advisor prompts us to rephrase:
@Test
void givenSafeGuardAdvisor_whenSendPromptWithSensitiveWord_thenExpectedMessageShouldBeReturned() {
List<String> forbiddenWords = List.of("Word2");
SafeGuardAdvisor safeGuardAdvisor = new SafeGuardAdvisor(forbiddenWords);
String responseContent = chatClient.prompt()
.user("Please split the 'Word2' into characters")
.advisors(safeGuardAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("I'm unable to respond to that due to sensitive content");
}6. Implement a Custom Advisor
Surely, we’re allowed to implement our custom advisors with any logic we need. Let’s create a CustomLoggingAdvisor where we’ll log all the chat requests and responses:
public class CustomLoggingAdvisor implements CallAroundAdvisor {
private final static Logger logger = LoggerFactory.getLogger(CustomLoggingAdvisor.class);
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
advisedRequest = this.before(advisedRequest);
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
this.observeAfter(advisedResponse);
return advisedResponse;
}
private void observeAfter(AdvisedResponse advisedResponse) {
logger.info(advisedResponse.response()
.getResult()
.getOutput()
.getContent());
}
private AdvisedRequest before(AdvisedRequest advisedRequest) {
logger.info(advisedRequest.userText());
return advisedRequest;
}
@Override
public String getName() {
return "CustomLoggingAdvisor";
}
@Override
public int getOrder() {
return Integer.MAX_VALUE;
}
}Here, we’ve implemented the CallAroundAdvisor interface and added the logging logic before and after the call. Additionally, we’ve returned the maximum integer value from the getOrder() method, so our adviser will be the very last in the chain.
Now, let’s test our new advisor:
@Test
void givenCustomLoggingAdvisor_whenSendPrompt_thenPromptTextAndResponseShouldBeLogged() {
CustomLoggingAdvisor customLoggingAdvisor = new CustomLoggingAdvisor();
String responseContent = chatClient.prompt()
.user("Count from 1 to 10")
.advisors(customLoggingAdvisor)
.call()
.content();
assertThat(responseContent)
.contains("1")
.contains("10");
}We’ve created the CustomLoggingAdvisor and attached it to the prompt. Let’s see what happens in the logs after the execution:
c.b.s.advisors.CustomLoggingAdvisor : Count from 1 to 10
c.b.s.advisors.CustomLoggingAdvisor : 1, 2, 3, 4, 5, 6, 7, 8, 9, 10As we can see, our advisor successfully logged the prompt text and chat response.
7. Conclusion
In this tutorial, we’ve explored a great Spring AI feature called Advisors. With Advisors, we gain chat memory capabilities, control over sensitive words, and seamless integration with the vector store. Additionally, we can easily create custom extensions to add specific functionality. Using Advisors allows us to achieve all of these capabilities consistently and straightforwardly.
As always, the code is available over on GitHub.






