1. Overview
This article introduces the LMAX Disruptor and talks about how it helps to achieve software concurrency with low latency. We will also see a basic usage of the Disruptor library.
2. What is a Disruptor?
Disruptor is an open source Java library written by LMAX. It is a concurrent programming framework for the processing of a large number of transactions, with low-latency (and without the complexities of concurrent code). The performance optimization is achieved by a software design that exploits the efficiency of underlying hardware.
2.1. Mechanical Sympathy
Let’s start with the core concept of mechanical sympathy – that is all about understanding how the underlying hardware operates and programming in a way that best works with that hardware.
For example, let’s see how CPU and memory organization can impact software performance. The CPU has several layers of cache between it and main memory. When the CPU is performing an operation, it first looks in L1 for the data, then L2, then L3, and finally, the main memory. The further it has to go, the longer the operation will take.
If the same operation is performed on a piece of data multiple times (for example, a loop counter), it makes sense to load that data into a place very close to the CPU.
Some indicative figures for the cost of cache misses:
| Latency from CPU to | CPU cycles | Time |
|---|---|---|
| Main memory | Multiple | ~60-80 ns |
| L3 cache | ~40-45 cycles | ~15 ns |
| L2 cache | ~10 cycles | ~3 ns |
| L1 cache | ~3-4 cycles | ~1 ns |
| Register | 1 cycle | Very very quick |
2.2. Why not Queues
Queue implementations tend to have write contention on the head, tail, and size variables. Queues are typically always close to full or close to empty due to the differences in pace between consumers and producers. They very rarely operate in a balanced middle ground where the rate of production and consumption is evenly matched.
To deal with the write contention, a queue often uses locks, which can cause a context switch to the kernel. When this happens the processor involved is likely to lose the data in its caches.
To get the best caching behavior, the design should have only one core writing to any memory location (multiple readers are fine, as processors often use special high-speed links between their caches). Queues fail the one-writer principle.
If two separate threads are writing to two different values, each core invalidates the cache line of the other (data is transferred between main memory and cache in blocks of fixed size, called cache lines). That is a write-contention between the two threads even though they’re writing to two different variables. This is called false sharing, because every time the head is accessed, the tail gets accessed too, and vice versa.
2.3. How the Disruptor Works
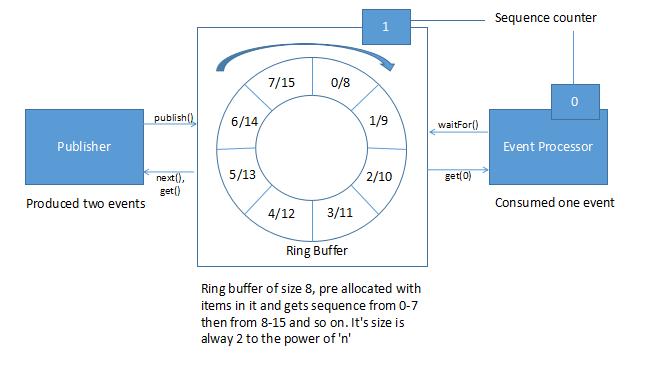
Disruptor has an array based circular data structure (ring buffer). It is an array that has a pointer to next available slot. It is filled with pre-allocated transfer objects. Producers and consumers perform writing and reading of data to the ring without locking or contention.
In a Disruptor, all events are published to all consumers (multicast), for parallel consumption through separate downstream queues. Due to parallel processing by consumers, it is necessary to coordinate dependencies between the consumers (dependency graph).
Producers and consumers have a sequence counter to indicate which slot in the buffer it is currently working on. Each producer/consumer can write its own sequence counter but can read other’s sequence counters. The producers and consumers read the counters to ensure the slot it wants to write in is available without any locks.
3. Using the Disruptor Library
3.1. Maven Dependency
Let’s start by adding Disruptor library dependency in pom.xml:
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.6</version>
</dependency>
The latest version of the dependency can be checked here.
3.2. Defining an Event
Let’s define the event that carries the data:
public static class ValueEvent {
private int value;
public final static EventFactory EVENT_FACTORY
= () -> new ValueEvent();
// standard getters and setters
}
The EventFactory lets the Disruptor preallocate the events.
3.3. Consumer
Consumers read data from the ring buffer. Let’s define a consumer that will handle the events:
public class SingleEventPrintConsumer {
...
public EventHandler<ValueEvent>[] getEventHandler() {
EventHandler<ValueEvent> eventHandler
= (event, sequence, endOfBatch)
-> print(event.getValue(), sequence);
return new EventHandler[] { eventHandler };
}
private void print(int id, long sequenceId) {
logger.info("Id is " + id
+ " sequence id that was used is " + sequenceId);
}
}
In our example, the consumer is just printing to a log.
3.4. Constructing the Disruptor
Construct the Disruptor:
ThreadFactory threadFactory = DaemonThreadFactory.INSTANCE;
WaitStrategy waitStrategy = new BusySpinWaitStrategy();
Disruptor<ValueEvent> disruptor
= new Disruptor<>(
ValueEvent.EVENT_FACTORY,
16,
threadFactory,
ProducerType.SINGLE,
waitStrategy);
In the constructor of Disruptor, the following are defined:
- Event Factory – Responsible for generating objects which will be stored in ring buffer during initialization
- The size of Ring Buffer – We have defined 16 as the size of the ring buffer. It has to be a power of 2 else it would throw an exception while initialization. This is important because it is easy to perform most of the operations using logical binary operators e.g. mod operation
- Thread Factory – Factory to create threads for event processors
- Producer Type – Specifies whether we will have single or multiple producers
- Waiting strategy – Defines how we would like to handle slow subscriber who doesn’t keep up with producer’s pace
Connect the consumer handler:
disruptor.handleEventsWith(getEventHandler());
It is possible to supply multiple consumers with Disruptor to handle the data that is produced by producer. In the example above, we have just one consumer a.k.a. event handler.
3.5. Starting the Disruptor
To start the Disruptor:
RingBuffer<ValueEvent> ringBuffer = disruptor.start();
3.6. Producing and Publishing Events
Producers place the data in the ring buffer in a sequence. Producers have to be aware of the next available slot so that they don’t overwrite data that is not yet consumed.
Use the RingBuffer from Disruptor for publishing:
for (int eventCount = 0; eventCount < 32; eventCount++) {
long sequenceId = ringBuffer.next();
ValueEvent valueEvent = ringBuffer.get(sequenceId);
valueEvent.setValue(eventCount);
ringBuffer.publish(sequenceId);
}
Here, the producer is producing and publishing items in sequence. It is important to note here that Disruptor works similar to 2 phase commit protocol. It reads a new sequenceId and publishes. The next time it should get sequenceId + 1 as the next sequenceId.
4. Conclusion
In this tutorial, we have seen what a Disruptor is and how it achieves concurrency with low latency. We have seen the concept of mechanical sympathy and how it may be exploited to achieve low latency. We have then seen an example using the Disruptor library.
The example code can be found in the GitHub project – this is a Maven based project, so it should be easy to import and run as is.