
1. Overview
The use of AI technologies is becoming a key skill in modern development. In this article, we’ll build a RAG Wiki application that can answer questions based on stored documents.
We’ll use Spring AI to integrate our application with the MongoDB Vector database and the LLM.
2. RAG Applications
We use Retrieval-Augmented Generation (RAG) applications when natural language generation needs to rely on contextual data. A key component of RAG applications is the vector database, which plays a crucial role in effectively managing and retrieving this data:
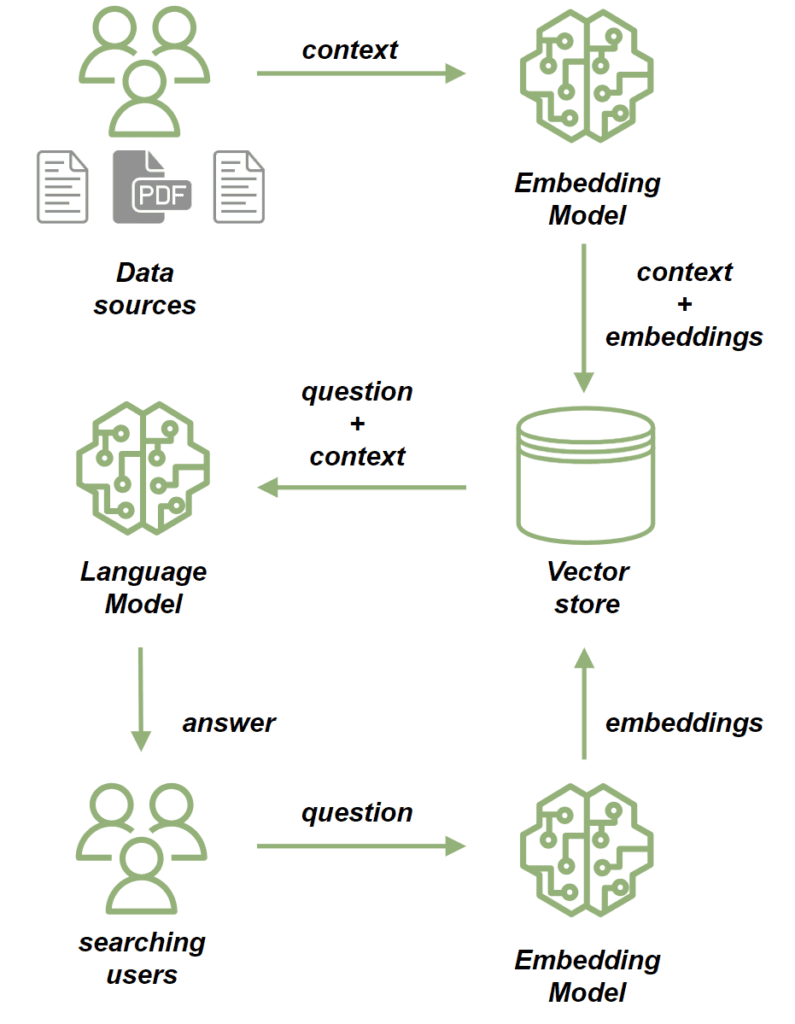
We use an embedding model to process source documents. The embedding model converts the text from our documents into high-dimensional vectors. These vectors capture the semantic meaning of the content, allowing us to compare and retrieve similar content based on context rather than just keyword matching. Then we store the documents in the vector store.
Once we’ve saved the documents, we can send prompts based on them in the following way:
- First, we use the embedding model to process the question, converting it into a vector that captures its semantic meaning.
- Next, we perform a similarity search, comparing the question’s vector with the vectors of documents stored in the vector store.
- From the most relevant documents, we build a context for the question.
- Finally, we send both the question and its context to the LLM, which constructs a response relevant to the query and enriched by the context provided.
3. MongoDB Atlas Vector Search
In this tutorial, we’ll use MongoDB Atlas Search as our vector store. It provides vector search capabilities that cover our needs in this project. To set the local instance of the MongoDB Atlas Search for test purposes, we’ll use the mongodb-atlas-local docker container. Let’s create a docker-compose.yml file:
version: '3.1'
services:
my-mongodb:
image: mongodb/mongodb-atlas-local:7.0.9
container_name: my-mongodb
environment:
- MONGODB_INITDB_ROOT_USERNAME=wikiuser
- MONGODB_INITDB_ROOT_PASSWORD=password
ports:
- 27017:270174. Dependencies and Configuration
Let’s begin by adding the necessary dependencies. Since our application will offer an HTTP API, we’ll include the spring-boot-starter-web dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>LATEST_VERSION</version>
</dependency>Additionally, we’ll be using the open AI API client to connect to LLM, so let’s add its dependency as well:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>LATEST_VERSION</version>
</dependency>Finally, we’ll add the MongoDB Atlas Store dependency:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mongodb-atlas-store-spring-boot-starter</artifactId>
<version>LATEST_VERSION</version>
</dependency>Now, let’s add the configuration properties for our application:
spring:
data:
mongodb:
uri: mongodb://wikiuser:password@localhost:27017/admin
database: wiki
ai:
vectorstore:
mongodb:
collection-name: vector_store
initialize-schema: true
path-name: embedding
indexName: vector_index
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-3.5-turboWe’ve specified the MongoDB URL and database, and we’ve also configured our vector store by setting the collection name, embedding field name, and vector index name. Thanks to the initialize-schema property, all of these artifacts will be automatically created by the Spring AI framework.
Finally, we’ve added the open AI API key and the model version.
5. Save Documents to the Vector Store
Now, we’re adding the process for saving data to our vector store. Our application will be responsible for providing answers to user questions based on existing documents – essentially functioning as a kind of wiki.
Let’s add a model that will store the content of the files along with the file path:
public class WikiDocument {
private String filePath;
private String content;
// standard getters and setters
}Next step, we’ll add the WikiDocumentsRepository. In this repository, we’re encapsulating all the persistence logic:
import org.springframework.ai.document.Document;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
@Component
public class WikiDocumentsRepository {
private final VectorStore vectorStore;
public WikiDocumentsRepository(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public void saveWikiDocument(WikiDocument wikiDocument) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("filePath", wikiDocument.getFilePath());
Document document = new Document(wikiDocument.getContent(), metadata);
List<Document> documents = new TokenTextSplitter().apply(List.of(document));
vectorStore.add(documents);
}
}
Here, we’ve injected the VectorStore interface bean, which will be implemented by MongoDBAtlasVectorStore provided by the spring-ai-mongodb-atlas-store-spring-boot-starter. In the saveWikiDocument method, we create a Document instance and populate it with the content and metadata.
Then we use TokenTextSplitter to break the document into smaller chunks and save them in our vector store. Now let’s create a WikiDocumentsServiceImpl:
@Service
public class WikiDocumentsServiceImpl {
private final WikiDocumentsRepository wikiDocumentsRepository;
// constructors
public void saveWikiDocument(String filePath) {
try {
String content = Files.readString(Path.of(filePath));
WikiDocument wikiDocument = new WikiDocument();
wikiDocument.setFilePath(filePath);
wikiDocument.setContent(content);
wikiDocumentsRepository.saveWikiDocument(wikiDocument);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}At the service layer, we retrieve the file contents, create WikiDocument instances, and send them to the repository for persistence.
In the controller, we’ll simply pass the file path to the service layer and return a 201 status code if the document is saved successfully:
@RestController
@RequestMapping("wiki")
public class WikiDocumentsController {
private final WikiDocumentsServiceImpl wikiDocumentsService;
// constructors
@PostMapping
public ResponseEntity<Void> saveDocument(@RequestParam String filePath) {
wikiDocumentsService.saveWikiDocument(filePath);
return ResponseEntity.status(201).build();
}
}Now, let’s start our application and see how our flow works. Let’s add the Spring Boot test dependency, which will allow us to set up a test web context:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>LATEST_VERSION</version>
</dependency>Now, we’ll bootstrap the test application instance and call the POST endpoint for two documents:
@AutoConfigureMockMvc
@ExtendWith(SpringExtension.class)
@SpringBootTest
class RAGMongoDBApplicationManualTest {
@Autowired
private MockMvc mockMvc;
@Test
void givenMongoDBVectorStore_whenCallingPostDocumentEndpoint_thenExpectedResponseCodeShouldBeReturned() throws Exception {
mockMvc.perform(post("/wiki?filePath={filePath}",
"src/test/resources/documentation/owl-documentation.md"))
.andExpect(status().isCreated());
mockMvc.perform(post("/wiki?filePath={filePath}",
"src/test/resources/documentation/rag-documentation.md"))
.andExpect(status().isCreated());
}
}Both calls should return a 201 status code, so the documents were added. We can use MongoDB Compass to confirm that the documents were successfully saved to the vector store:

As we can see – both documents were saved. We can see the original content as well as an embedding array.
6. Similarity Search
Let’s add the similarity search functionality. We’ll include a findSimilarDocuments method in our repository:
@Component
public class WikiDocumentsRepository {
private final VectorStore vectorStore;
public List<WikiDocument> findSimilarDocuments(String searchText) {
return vectorStore
.similaritySearch(SearchRequest
.query(searchText)
.withSimilarityThreshold(0.87)
.withTopK(10))
.stream()
.map(document -> {
WikiDocument wikiDocument = new WikiDocument();
wikiDocument.setFilePath((String) document.getMetadata().get("filePath"));
wikiDocument.setContent(document.getContent());
return wikiDocument;
})
.toList();
}
}We’ve called the similaritySearch method from the VectorStore. In addition to the search text, we’ve specified a result limit and a similarity threshold. The similarity threshold parameter allows us to control how closely the document content should match our search text.
In the service layer, we’ll proxy the call to the repository:
public List<WikiDocument> findSimilarDocuments(String searchText) {
return wikiDocumentsRepository.findSimilarDocuments(searchText);
}In the controller, let’s add a GET endpoint that receives the search text as a parameter and passes it to the service:
@RestController
@RequestMapping("/wiki")
public class WikiDocumentsController {
@GetMapping
public List<WikiDocument> get(@RequestParam("searchText") String searchText) {
return wikiDocumentsService.findSimilarDocuments(searchText);
}
}Now let’s call our new endpoint and see how the similarity search works:
@Test
void givenMongoDBVectorStoreWithDocuments_whenMakingSimilaritySearch_thenExpectedDocumentShouldBePresent() throws Exception {
String responseContent = mockMvc.perform(get("/wiki?searchText={searchText}", "RAG Application"))
.andExpect(status().isOk())
.andReturn()
.getResponse()
.getContentAsString();
assertThat(responseContent)
.contains("RAG AI Application is responsible for storing the documentation");
}We called the endpoint with a search text that wasn’t an exact match in the document. However, we still retrieved the document with similar content and confirmed that it contained the text we stored in our rag-documentation.md file.
7. Prompt Endpoint
Let’s start building the prompt flow, which is the core functionality of our application. We’ll begin with the AdvisorConfiguration:
@Configuration
public class AdvisorConfiguration {
@Bean
public QuestionAnswerAdvisor questionAnswerAdvisor(VectorStore vectorStore) {
return new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults());
}
}We’ve created a QuestionAnswerAdvisor bean, responsible for constructing the prompt request, including the initial question. Additionally, it will attach the vector store’s similarity search response as context for the question. Now, let’s add the search endpoint to our API:
@RestController
@RequestMapping("/wiki")
public class WikiDocumentsController {
private final WikiDocumentsServiceImpl wikiDocumentsService;
private final ChatClient chatClient;
private final QuestionAnswerAdvisor questionAnswerAdvisor;
public WikiDocumentsController(WikiDocumentsServiceImpl wikiDocumentsService,
@Qualifier("openAiChatModel") ChatModel chatModel,
QuestionAnswerAdvisor questionAnswerAdvisor) {
this.wikiDocumentsService = wikiDocumentsService;
this.questionAnswerAdvisor = questionAnswerAdvisor;
this.chatClient = ChatClient.builder(chatModel).build();
}
@GetMapping("/search")
public String getWikiAnswer(@RequestParam("question") String question) {
return chatClient.prompt()
.user(question)
.advisors(questionAnswerAdvisor)
.call()
.content();
}
}
Here, we’ve constructed a prompt request by adding the user’s input to the prompt and attaching our QuestionAnswerAdvisor.
Finally, let’s call our endpoint and see what it tells us about RAG applications:
@Test
void givenMongoDBVectorStoreWithDocumentsAndLLMClient_whenAskQuestionAboutRAG_thenExpectedResponseShouldBeReturned() throws Exception {
String responseContent = mockMvc.perform(get("/wiki/search?question={question}", "Explain the RAG Applications"))
.andExpect(status().isOk())
.andReturn()
.getResponse()
.getContentAsString();
logger.atInfo().log(responseContent);
assertThat(responseContent).isNotEmpty();
}We sent the question “Explain the RAG applications” to our endpoint and logged the API response:
b.s.r.m.RAGMongoDBApplicationManualTest : Based on the context provided, the RAG AI Application is a tool
used for storing documentation and enabling users to search for specific information efficiently...As we can see, the endpoint returned information about RAG applications based on the documentation files we previously saved in the vector database.
Now let’s try to ask something that we surely don’t have in our knowledge base:
@Test
void givenMongoDBVectorStoreWithDocumentsAndLLMClient_whenAskUnknownQuestion_thenExpectedResponseShouldBeReturned() throws Exception {
String responseContent = mockMvc.perform(get("/wiki/search?question={question}", "Explain the Economic theory"))
.andExpect(status().isOk())
.andReturn()
.getResponse()
.getContentAsString();
logger.atInfo().log(responseContent);
assertThat(responseContent).isNotEmpty();
}Now we’ve asked about economic theory, and here is the response:
b.s.r.m.RAGMongoDBApplicationManualTest : I'm sorry, but the economic theory is not directly related to the information provided about owls and the RAG AI Application.
If you have a specific question about economic theory, please feel free to ask.This time, our application didn’t find any related documents and didn’t use any other sources to provide an answer.
8. Conclusion
In this article, we successfully implemented an RAG application using the Spring AI framework, which is an excellent tool for integrating various AI technologies. Additionally, MongoDB proves to be a strong choice for handling vector storage.
With this powerful combination, we can build modern AI-based applications for various purposes, including chatbots, automated wiki systems, and search engines.
As always, the code is available over on GitHub.






