1. Introduction
AWS offers many services through its many APIs which we can access from Java using their official SDK. Until recently though, this SDK didn’t offer support for reactive operations and had only limited support for asynchronous access.
With the release of the AWS SDK for Java 2.0, we can now use those APIs in fully non-blocking I/O mode, thanks to its adopting the Reactive Streams standard.
In this tutorial, we’ll explore those new features by implementing a simple blob store REST API in Spring Boot that uses the well-known S3 service as its storage backend.
2. Overview of AWS S3 Operations
Before diving into the implementation, let’s do a quick overview of what we want to achieve here. A typical blob store service exposes CRUD operations that a front-end application consumes to allow an end-user to upload, list, download and delete several types of content, such as audio, pictures, and documents.
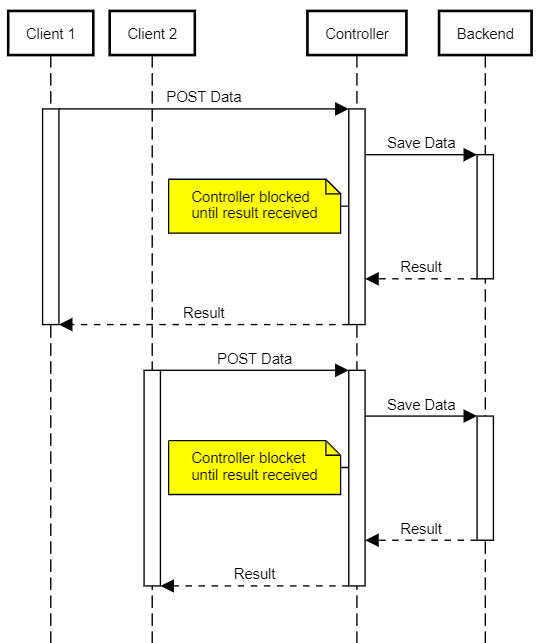
A common issue that traditional implementations must deal with is how to efficiently handle large files or slow connections. In early versions (pre-servlet 3.0), all the JavaEE spec had to offer was a blocking API, so we needed a thread for each concurrent blob store client. This model has the drawback that requires more server resources (ergo, bigger machines) and turns them more vulnerable to DoS-type attacks:
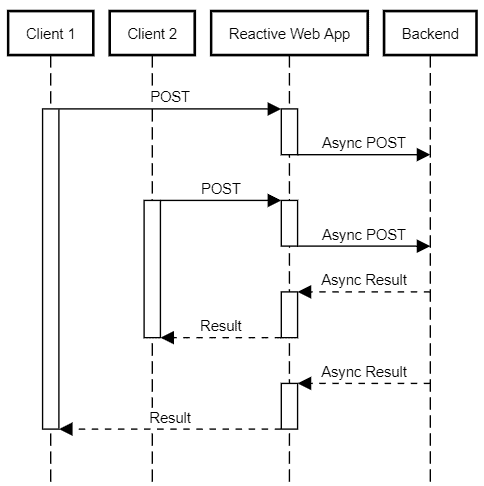
By using a reactive stack, we can make our service much less resource-intensive for the same number of clients. The reactor implementation uses a small number of threads that are dispatched in response to I/O completion events, such as the availability of new data to read or the completion of a previous write.
This means that the same thread keeps going on handling those events – which can originate from any of the active client connections – until there is no more available work to do. This approach greatly reduces the number of context switches – a quite expensive operation – and allows for very efficient use of the available resources:
3. Project Setup
Our demo project is a standard Spring Boot WebFlux application which includes the usual support dependencies, such as Lombok and JUnit.
In addition to those libraries, we need to bring in the AWS SDK for Java V2 dependencies:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.10.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<scope>compile</scope>
</dependency>
<dependency>
<artifactId>netty-nio-client</artifactId>
<groupId>software.amazon.awssdk</groupId>
<scope>compile</scope>
</dependency>
</dependencies>
The AWS SDK provides a BOM defining the required versions for all dependencies, so we don't need to specify them in the dependencies section of our POM file.
We've added the S3 client library, which will bring along other core dependencies from the SDK. We also need the Netty client library, required since we'll be using asynchronous APIs to interact with AWS.
The official AWS documentation contains more details on the available transports.
4. AWS S3 Client Creation
The entry point for S3 operations is the S3AsyncClient class, which we'll use to start new API calls.
As we only need a single instance of this class, let's create a @Configuration class with a @Bean method that builds it, so we can inject it wherever we need it:
@Configuration
@EnableConfigurationProperties(S3ClientConfigurarionProperties.class)
public class S3ClientConfiguration {
@Bean
public S3AsyncClient s3client(S3ClientConfigurarionProperties s3props,
AwsCredentialsProvider credentialsProvider) {
SdkAsyncHttpClient httpClient = NettyNioAsyncHttpClient.builder()
.writeTimeout(Duration.ZERO)
.maxConcurrency(64)
.build();
S3Configuration serviceConfiguration = S3Configuration.builder()
.checksumValidationEnabled(false)
.chunkedEncodingEnabled(true)
.build();
S3AsyncClientBuilder b = S3AsyncClient.builder().httpClient(httpClient)
.region(s3props.getRegion())
.credentialsProvider(credentialsProvider)
.serviceConfiguration(serviceConfiguration);
if (s3props.getEndpoint() != null) {
b = b.endpointOverride(s3props.getEndpoint());
}
return b.build();
}
}
For this demo, we're using a minimal @ConfigurationProperties class (available at our repository) that holds the following pieces of information required to access S3 services:
- region: A valid AWS region identifier, such as us-east-1
- accessKeyId/secretAccessKey: Our AWS API key and identifier
- endpoint: An optional URI that we can use to override S3's default service endpoint. The main use case is to use the demo code with alternative storage solutions that offer an S3-compatible API (minio and localstack are examples)
- bucket: Name of the bucket where we'll store uploaded files
There are a few points worth mentioning about the client's initialization code. First, we're disabling write timeouts and increasing the maximum concurrency, so uploads can complete even under low-bandwidth situations.
Second, we're disabling checksum validation and enabling chunked encoding. We're doing this because we want to start uploading data to the bucket as soon as the data arrives at our service in a streaming fashion.
Finally, we're not addressing the bucket creation itself, as we're assuming it's been already created and configured by an administrator.
As for the credentials, we supply a customized AwsCredentialsProvider that can recover the credentials from Spring properties. This opens the possibility to inject those values through Spring's Environment abstraction and all its supported PropertySource implementations, such as Vault or Config Server:
@Bean
public AwsCredentialsProvider awsCredentialsProvider(S3ClientConfigurarionProperties s3props) {
if (StringUtils.isBlank(s3props.getAccessKeyId())) {
return DefaultCredentialsProvider.create();
} else {
return () -> {
return AwsBasicCredentials.create(
s3props.getAccessKeyId(),
s3props.getSecretAccessKey());
};
}
}
5. Upload Service Overview
We'll now implement an upload service, which we'll be reachable at the /inbox path.
A POST to this resource path will store the file at our S3 bucket under a randomly generated key. We'll store the original filename as a metadata key, so we can use it to generate the appropriate HTTP download headers for browsers.
We need to handle two distinct scenarios: simple and multi-part uploads. Let's go ahead and create a @RestController and add methods to handle those scenarios:
@RestController
@RequestMapping("/inbox")
@Slf4j
public class UploadResource {
private final S3AsyncClient s3client;
private final S3ClientConfigurarionProperties s3config;
public UploadResource(S3AsyncClient s3client, S3ClientConfigurarionProperties s3config) {
this.s3client = s3client;
this.s3config = s3config;
}
@PostMapping
public Mono<ResponseEntity<UploadResult>> uploadHandler(
@RequestHeader HttpHeaders headers,
@RequestBody Flux<ByteBuffer> body) {
// ... see section 6
}
@RequestMapping(
consumes = MediaType.MULTIPART_FORM_DATA_VALUE,
method = {RequestMethod.POST, RequestMethod.PUT})
public Mono<ResponseEntity<UploadResult>> multipartUploadHandler(
@RequestHeader HttpHeaders headers,
@RequestBody Flux<Part> parts ) {
// ... see section 7
}
}
Handler signatures reflect the main difference between both cases: In the simple case, the body contains the file content itself, whereas in the multipart case it can have multiple “parts”, each corresponding to a file or form data.
As a convenience, we'll support multipart uploads using POST or PUT methods. The reason for this is that some tools (cURL, notably) use the latter by default when uploading files with the -F option.
In both cases, we'll return an UploadResult containing the result of the operation and the generated file keys that a client should use to recover the original files – more on this later!
6. Single File Upload
In this case, clients send content in a simple POST operation with the request body containing raw data. To receive this content in a Reactive Web application, all we have to do is to declare a @PostMapping method that takes a Flux<ByteBuffer> argument.
Streaming this flux to a new S3 file is straightforward in this case.
All we need is to build a PutObjectRequest with a generated key, file length, MIME content-type and pass it to the putObject() method in our S3 client:
@PostMapping
public Mono<ResponseEntity<UploadResult>> uploadHandler(@RequestHeader HttpHeaders headers,
@RequestBody Flux<ByteBuffer> body) {
// ... some validation code omitted
String fileKey = UUID.randomUUID().toString();
MediaType mediaType = headers.getContentType();
if (mediaType == null) {
mediaType = MediaType.APPLICATION_OCTET_STREAM;
}
CompletableFuture future = s3client
.putObject(PutObjectRequest.builder()
.bucket(s3config.getBucket())
.contentLength(length)
.key(fileKey.toString())
.contentType(mediaType.toString())
.metadata(metadata)
.build(),
AsyncRequestBody.fromPublisher(body));
return Mono.fromFuture(future)
.map((response) -> {
checkResult(response);
return ResponseEntity
.status(HttpStatus.CREATED)
.body(new UploadResult(HttpStatus.CREATED, new String[] {fileKey}));
});
}
The key point here is how we're passing the incoming Flux to the putObject() method.
This method expects an AsyncRequestBody object that provides content on demand. Basically, it's a regular Publisher with some extra convenience methods. In our case, we'll take benefit from the fromPublisher() method to convert our Flux into the required type.
Also, we assume that the client will send the Content-Length HTTP header with the correct value. Without this information, the call will fail since this is a required field.
Asynchronous methods in the SDK V2 always return a CompletableFuture object. We take it and adapt it to a Mono using its fromFuture() factory method. This gets mapped to the final UploadResult object.
7. Uploading Multiple Files
Handling a multipart/form-data upload may seem easy, especially when using libraries that handle all details for us. So, can we simply use the previous method for each uploaded file? Well, yes, but this comes with a price: Buffering.
To use the previous method, we need the part's length, but chunked file transfers do not always include this information. One approach is to store the part in a temporary file and then send it to AWS, but this will slow down the total upload time. It also means extra storage for our servers.
As an alternative, here we'll use an AWS multipart upload. This feature allows the upload of a single file to be split in multiple chunks that we can send in parallel and out of order.
The steps are as follows, we need to send:
- the createMultipartUpload request – AWS responds with an uploadId that we'll use in the next calls
- file chunks containing the uploadId, sequence number and content – AWS responds with an ETag identifier for each part
- a completeUpload request containing the uploadId and all ETags received
Please note: We'll repeat those steps for each received FilePart!
7.1. Top-Level Pipeline
The multipartUploadHandler in our @Controller class is responsible for handling, not surprisingly, multipart file uploads. In this context, each part can have any kind of data, identified by its MIME-type. The Reactive Web framework delivers those parts to our handler as a Flux of objects that implement the Part interface, which we'll process in turn:
return parts .ofType(FilePart.class) .flatMap((part)-> saveFile(headers, part)) .collect(Collectors.toList()) .map((keys)-> new UploadResult(HttpStatus.CREATED, keys)));
This pipeline starts by filtering parts that correspond to an actual uploaded file, which will always be an object that implements the FilePart interface. Each part is then passed to the saveFile method, which handles the actual upload for a single file and returns the generated file key.
We collect all keys in a List and, finally, build the final UploadResult. We're always creating a new resource, so we'll return a more descriptive CREATED status (202) instead of a regular OK.
7.2. Handling a Single File Upload
We've already outlined the steps required to upload a file using AWS's multipart method. There's a catch, though: The S3 service requires that each part, except the last one, must have a given minimum size – 5 MBytes, currently.
This means that we can't just take the received chunks and send them right away. Instead, we need to buffer them locally until we reach the minimum size or end of data. Since we also need a place to track how many parts we've sent and the resulting CompletedPart results, we'll create a simple UploadState inner class to hold this state:
class UploadState {
String bucket;
String filekey;
String uploadId;
int partCounter;
Map<Integer, CompletedPart> completedParts = new HashMap<>();
int buffered = 0;
// ... getters/setters omitted
UploadState(String bucket, String filekey) {
this.bucket = bucket;
this.filekey = filekey;
}
}
Given the required steps and buffering, we end up with implementation may look a bit intimidating at first glance:
Mono<String> saveFile(HttpHeaders headers,String bucket, FilePart part) {
String filekey = UUID.randomUUID().toString();
Map<String, String> metadata = new HashMap<String, String>();
String filename = part.filename();
if ( filename == null ) {
filename = filekey;
}
metadata.put("filename", filename);
MediaType mt = part.headers().getContentType();
if ( mt == null ) {
mt = MediaType.APPLICATION_OCTET_STREAM;
}
UploadState uploadState = new UploadState(bucket,filekey);
CompletableFuture<CreateMultipartUploadResponse> uploadRequest = s3client
.createMultipartUpload(CreateMultipartUploadRequest.builder()
.contentType(mt.toString())
.key(filekey)
.metadata(metadata)
.bucket(bucket)
.build());
return Mono
.fromFuture(uploadRequest)
.flatMapMany((response) -> {
checkResult(response);
uploadState.uploadId = response.uploadId();
return part.content();
})
.bufferUntil((buffer) -> {
uploadState.buffered += buffer.readableByteCount();
if ( uploadState.buffered >= s3config.getMultipartMinPartSize() ) {
uploadState.buffered = 0;
return true;
} else {
return false;
}
})
.map((buffers) -> concatBuffers(buffers))
.flatMap((buffer) -> uploadPart(uploadState,buffer))
.reduce(uploadState,(state,completedPart) -> {
state.completedParts.put(completedPart.partNumber(), completedPart);
return state;
})
.flatMap((state) -> completeUpload(state))
.map((response) -> {
checkResult(response);
return uploadState.filekey;
});
}
We start by collecting some file metadata and using it to create a request object required by the createMultipartUpload() API call. This call returns a CompletableFuture, which is the starting point for our streaming pipeline.
Let's review what each step of this pipeline does:
- After receiving the initial result, which contains the S3's generated uploadId, we save it in the upload state object and start streaming the file's body. Notice the use of flatMapMany here, which turns the Mono into a Flux
- We use bufferUntil() to accumulate the required number of bytes. The pipeline at this point changes from a Flux of DataBuffer objects into a Flux of List<DataBuffer> objects
- Convert each List<DataBuffer> to a ByteBuffer
- Send the ByteBuffer to S3 (see next section) and return the resulting CompletedPart value downstream
- Reduce the resulting CompletedPart values into the uploadState
- Signals S3 that we've completed the upload (more on this later)
- Return the generated file key
7.3. Uploading File Parts
Once again, let's make clear that a “file part” here means a piece of a single file (for example, the first 5MB of a 100MB file), not a part of a message that happens to be a file, as it is in the top-level stream!
The file upload pipeline calls the uploadPart() method with two arguments: the upload state and a ByteBuffer. From there, we build a UploadPartRequest instance and use the uploadPart() method available in our S3AsyncClient to send the data:
private Mono<CompletedPart> uploadPart(UploadState uploadState, ByteBuffer buffer) {
final int partNumber = ++uploadState.partCounter;
CompletableFuture<UploadPartResponse> request = s3client.uploadPart(UploadPartRequest.builder()
.bucket(uploadState.bucket)
.key(uploadState.filekey)
.partNumber(partNumber)
.uploadId(uploadState.uploadId)
.contentLength((long) buffer.capacity())
.build(),
AsyncRequestBody.fromPublisher(Mono.just(buffer)));
return Mono
.fromFuture(request)
.map((uploadPartResult) -> {
checkResult(uploadPartResult);
return CompletedPart.builder()
.eTag(uploadPartResult.eTag())
.partNumber(partNumber)
.build();
});
}
Here, we use the return value from the uploadPart() request to build a CompletedPart instance. This is an AWS SDK type that we'll need later when building the final request that closes the upload.
7.4. Completing the Upload
Last, but not least, we need to finish the multi-part file upload by sending a completeMultipartUpload() request to S3. This is quite easy given that the upload pipeline passes all the information we need as arguments:
private Mono<CompleteMultipartUploadResponse> completeUpload(UploadState state) {
CompletedMultipartUpload multipartUpload = CompletedMultipartUpload.builder()
.parts(state.completedParts.values())
.build();
return Mono.fromFuture(s3client.completeMultipartUpload(CompleteMultipartUploadRequest.builder()
.bucket(state.bucket)
.uploadId(state.uploadId)
.multipartUpload(multipartUpload)
.key(state.filekey)
.build()));
}
8. Downloading Files from AWS
Compared to multi-part uploads, downloading objects from an S3 bucket is a much simpler task. In this case, we don't have to worry about chunks or anything like that. The SDK API provides the getObject() method that takes two arguments:
- A GetObjectRequest object containing the requested bucket and file key
- An AsyncResponseTransformer, which allows us to map an incoming streaming response to something else
The SDK provides a couple of implementations of the latter that make it possible to adapt the stream to a Flux, but, again, at a cost: they buffer data internally in an array buffer. As this buffering results in poor response time for a client of our demo service, we'll implement our own adapter – which is not a big deal, as we'll see.
8.1. Download Controller
Our download controller is a standard Spring Reactive @RestController, with a single @GetMapping method that handles download requests. We expect the file key through a @PathVariable argument and we'll return an asynchronous ResponseEntity with the file's content:
@GetMapping(path="/{filekey}")
Mono<ResponseEntity<Flux<ByteBuffer>>> downloadFile(@PathVariable("filekey") String filekey) {
GetObjectRequest request = GetObjectRequest.builder()
.bucket(s3config.getBucket())
.key(filekey)
.build();
return Mono.fromFuture(s3client.getObject(request,new FluxResponseProvider()))
.map(response -> {
checkResult(response.sdkResponse);
String filename = getMetadataItem(response.sdkResponse,"filename",filekey);
return ResponseEntity.ok()
.header(HttpHeaders.CONTENT_TYPE, response.sdkResponse.contentType())
.header(HttpHeaders.CONTENT_LENGTH, Long.toString(response.sdkResponse.contentLength()))
.header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + filename + "\"")
.body(response.flux);
});
}
Here, getMetadataItem() is just a helper method that looks up a given metadata key in the response in a case-insensitive way.
This is an important detail: S3 returns metadata information using special HTTP headers, but those headers are case insensitive (see RFC 7230, section 3.2). This means that implementations may change the case for a given item at will – and this actually happens when using MinIO.
8.2. FluxResponseProvider Implementation
Our FluxReponseProvider must implement the AsyncResponseTransformer interface, which has only four methods:
- prepare(), where we can do any required setup
- onResponse(), called when S3 returns response status and metadata
- onStream() called when the response has a body, always after onResponse()
- exceptionOccurred() called in the event of some error
This provider's job is to handle those events and create a FluxResponse instance, containing both the provided GetObjectResponse instance and the response body as a stream:
class FluxResponseProvider implements AsyncResponseTransformer<GetObjectResponse,FluxResponse> {
private FluxResponse response;
@Override
public CompletableFuture<FluxResponse> prepare() {
response = new FluxResponse();
return response.cf;
}
@Override
public void onResponse(GetObjectResponse sdkResponse) {
this.response.sdkResponse = sdkResponse;
}
@Override
public void onStream(SdkPublisher<ByteBuffer> publisher) {
response.flux = Flux.from(publisher);
response.cf.complete(response);
}
@Override
public void exceptionOccurred(Throwable error) {
response.cf.completeExceptionally(error);
}
}
Finally, let's take a quick look at the FluxResponse class:
class FluxResponse {
final CompletableFuture<FluxResponse> cf = new CompletableFuture<>();
GetObjectResponse sdkResponse;
Flux<ByteBuffer> flux;
}
9. Conclusion
In this tutorial, we've covered the basics of using the reactive extensions available in the AWS SDK V2 library. Our focus here was the AWS S3 service, but we can extend the same techniques to other reactive-enabled services, such as DynamoDB.
As usual, all code is available over on GitHub.